

 Worldwide Locations
Worldwide LocationsAs I’ve stated before, I like Border Gateway Protocol (BGP). I think it’s an interesting protocol, and yes — it’s complicated, but I guess that part of why I like it. There are a lot of knobs to tweak in BGP, maybe too many, but that’s another post. Anyway, we are now running BGP version 4 and it has had extensions written that support more than just IPv4 unicast routing. We now have IPv4 multicast, IPv6 unicast and multicast, VPNv4, VPNv6, and a few others. As IPv6 becomes more common and we have to pass IPv6 routing information, we need to look at how we pass those routes. We can configure BGP to support IPv6 routes using a separate BGP session to IPv4, or we could consider using a single session to support both IPv4 and IPv6.
Running separate BGP sessions for IPv4 and IPv6 is currently the typical model. It is straightforward and easy to follow, but you are eating up more resources by having multiple TCP sessions and BGP peering relationships between BGP neighbors.
Running a single session to carry both address families works but tends to be a bit more confusing for some at first. There are additional steps to to take for making the routes usable, which are not needed if the peering is over the address family that the routes are in (IPv4 carried over IPv4 and IPv6 carried over IPv6). There are some savings on the routers in having only one TCP and BGP session, so this may be more attractive in the long term.
Same Address Family and Peering
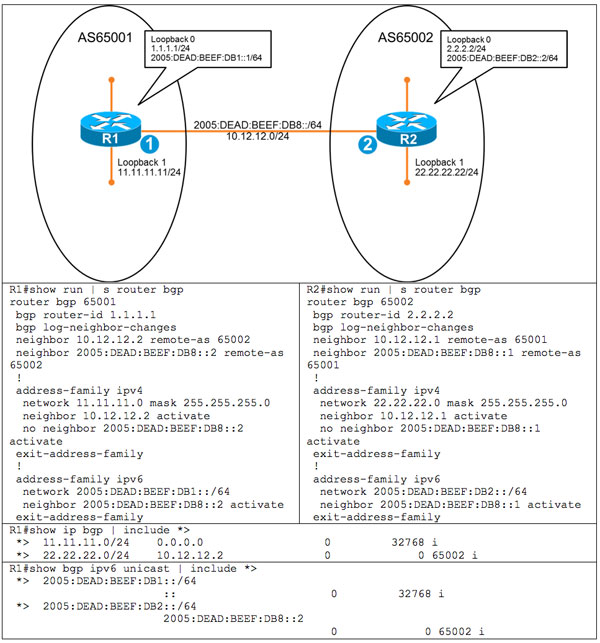
This is the typical implementation that I see today and the easiest to follow. We peer between BGP neighbors with IPv4 and pass IPv4-only routes. We then peer to the same neighbor, but over IPv6 and pass IPv6 routes. The protocols are separate and the logic is easy to follow. The following example shows the configuration and resulting tables for this type of implementation:
Cross Address Family and Peering
With this scenario, we can have a single session and peering between BGP routers that carry both IPv4 and IPv6. We could add the support for IPv6 to a pre-existing IPv4 relationship, or we could create a new relationship over IPv6 that carries both IPv4 and IPv6. The confusion could come from the fact there is only one relationship (let’s say that it’s over IPv4), but it’s receiving routes for a different address family (IPv6). The routers don’t get confused—only humans do.
The only real issue is the next hop attribute. The next hop has to be of the same address family as the route itself (IPv4 next hop for IPv4 route and IPv6 next hop for IPv6); otherwise, the route isn’t usable. The router will try to derive a next hop on its own but it tends to work only if you are configuring 6PE or 6VPE (IPv6 over MPLS with IPv4 neighbors in BGP). Otherwise, the next hop address that the router derives is not usable. This is the extra step that needs to be done, which isn’t needed for the previous option (where the same address family and address used for peering are in common (IPv4 Address family with IPv4 addressing for peering or IPv6 Address Family with IPv6 addressing for peering). We have to change the next hop address to something that is usable. This can be done on either the sending or receiving router. In either case, on IOS/IOS-XE routers — it will be done through a route map.
The first example shows IPv6 routes being carried over an IPv4 peering:

Notice that the next hop for the learned route now has an IPv4 mapped address (::FF:10.12.12.2). This would be usable if we were running MPLS between the BGP routers but since we are not, the next hop is inaccessible, and therefore the route is not usable and is not selected. To fix this, we need a route map to change the next hop:
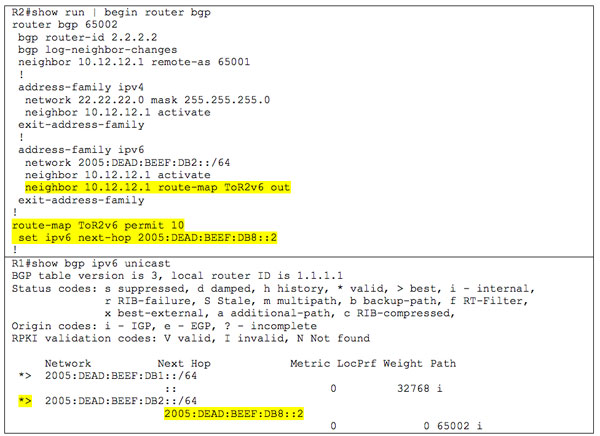
Now let’s reverse it and peer over IPv6 but pass IPv4 routes:
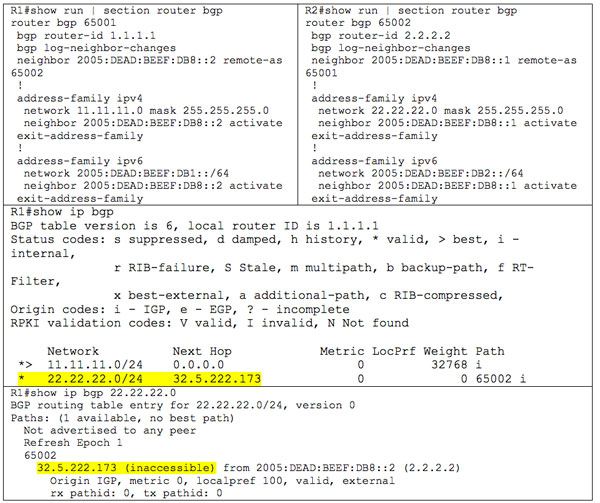
Notice that the next hop for the learned route now has an IPv4 address that is not known. This address is derived from the IPv6 address: 32 = 0x20, 5 =0x05, 222 = 0xDE, 173 = 0xAD…or 2005:DEAD. This is not a usable next hop. To fix this, we need a route map to change the next hop (as before):

There is a little extra effort here but as you can see, with one peering relationship, we can carry either IPv4 or IPv6 address family of routes over either IPv4 or IPv6 peering. In the long term, this would save on configuration and processing on the routers and make it easier to transition away from IPv4… in the short term, this is just a stupid CCIE trick.
Related Course
CIERS1 - CCIE 360 R&S Prep Boot Camp 1